
Jump to page sections
- Download
- Parameters
- Examples
- The Basic Example
- A Practical Walk-through/example
- Handling duplicate ID entries
- Alias Property Handling
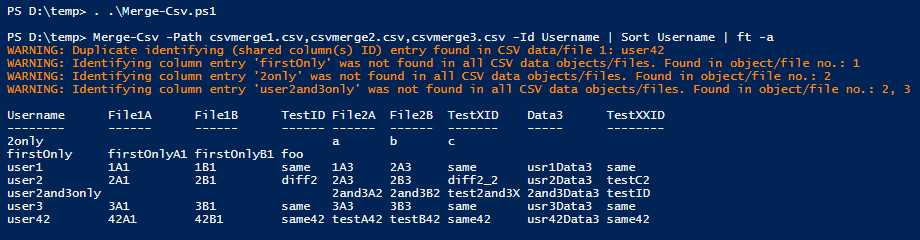
- Example of Merging Three Files
- Filtering the Merged Results
- Example of Merging Three Files Based on Two ID Columns
If you have two or more CSV files (or custom PowerShell objects) that share one or more columns/headers/properties, and you want to merge them based on this or these properties, say hello to Merge-Csv. The most typical scenario will be using only one ID column, such as a username that's common in two or more files, and you want for instance everything from one CSV file joined with a separate CSV file that has some info that's missing in the other one, and you want the username (or some other ID field - or fields) to be the thing(s) that tie(s) it together.
The code is not very efficient, but provides extreme convenience in certain situations. You have probably needed it - or been in a position where it would have been useful - several times before without even realizing. Have an object with a ComputerName property and a CSV file with a ComputerName property - and you want to "join" them? Throw Merge-Csv at them and marvel.
Since Import-Csv turns stuff into custom PowerShell objects, and this script works with those objects, I suppose the function could more accurately have been named "Merge-Object", but there it is.
It has been published to the PowerShell gallery here and is also on GitHub here. Or see the download section below.
Since writing this I also found out about Join-Object, written by the PowerShell team. It's quite different from mine. It only handles two CSV files / custom PS objects at a time. They have parameters to handle some of the filtering you would do with Where-Object using my function.
PowerShell version 3 or up is recommended.
I shamelessly mention that the "PowerShell Godfather" himself, Jeffrey Snover, found it worthy of mention as per this tweet. (By the way, my Twitter handle is not "joakimbs" anymore, the account was deleted; if it's in use now, it's not me).

For simple concatenation of two CSV files with shared headers, all you need is basically:
@(Import-Csv file1.csv) + @(Import-Csv file2.csv) | Export-Csv joined.csv
There's a more thorough article on simple concatenation/appending, "for dummies", here, written by the Microsoft scripting guys.
This Merge-Csv function also does some consistency checking on the merge and reports discrepancies, as seen here:
Download
I've now removed the link to the single .ps1 file. Please use the module. It's cumbersome to keep three versions updated, let alone four, which is why I'm now too lazy to update the stand-alone text file .ps1 as well. Just rename the module .psm1 to .ps1 and dot-source it to achieve the same thing.
MergeCsv.zip - v1.7.0.3 as a module. Requires minimum PowerShell version 3. Download and remember to unblock (Unblock-File), then copy the directory to a PowerShell module folder (see $Env:PSModulePath). Now also published to the PowerShell Gallery for easy installation and Merge-Csv is on GitHub here. GitHub will likely be updated first, then the PS Gallery, then the wiki (2023-06-29: It's not likely I will update the wiki anymore.).
*2017-12-12: v1.7.0.3. Doc fixes. Module metadata added (tags, file list).
*2017-09-13: v1.7.0.2 module uploaded. Now handles multiple ID properties better with -AllowDuplicates in use. Corrected a bug with meaningless objects being created instead of the more logical choice of empty strings.
*2017-09-13: v1.7 module uploaded. Added -IncludeAliasProperty as a non-default switch parameter. Changed -Id to the full form -Identity.
*2017-05-06: v1.6 module uploaded. UTF-8-encoded files, likely small changes some time in February.
*2017-01-23: uploading module version 1.5. Replaced "Sort" with "Sort-Object" for PowerShell v6 compatibility on Linux.
*2016-10-28: v1.4 uploaded as a module (in the MergeCsv.zip file above).
*2016-09-16: v1.4. Duplicate IDs can now be presented in an aggregated manner rather than simply being filtered out, by using the -AllowDuplicates parameter.
*2014-07-16: Fixed so it handles spaces in headers.
*2014-03-18: Uploaded new version with -Id instead of -SharedColumn, and regex escaping of the optional -Separator that's used with the -split operator. Updated screenshots and documentation.
*2014-02-03: Worked around a bug (in a stupid way) that occurs when working with only two files and the first file has an ID that's not in the second file. It would report "none". Now it correctly reports "1".
*Latest uploaded version:
Merge-Csv.ps1.txt.
*Latest uploaded version of the module:
MergeCsv.zip.
NB! These links above are old. Use GitHub or the PowerShell Gallery for the most recent version.
If you have Windows Management Framework 5 or higher (WMF 5 is available for Windows 7 / Server 2008 R2 and up), you can install my MergeCsv module from the PowerShell gallery, a Microsoft site and online repository for scripts.
To install with WMF 5 and up (to get the latest MergeCsv module version available), simply run this command (requires an internet connection):
Install-Module -Name MergeCsv #-Scope CurrentUser -Force
Parameters
| Identity | Shared columns/headers that serve as ID fields. Typically something like a username or computer name. |
| Path | Path to CSV files to merge. Cannot be used with -InputObject. |
| InputObject | Custom PowerShell objects to merge. Cannot be used with -Path. But you can pass in "-InputObject $obj, (Import-Csv csv1.csv)". |
| Delimiter | CSV delimiter character. |
| Separator | Default separator string used between multiple ID fields. Default is "#Merge-Csv-Separator#". Shouldn't ever have to be changed, but is here just in case you happen to have that string in your ID headers (this is not likely!). |
| AllowDuplicates | Allow duplicate IDs. Specify this to prevent duplicate IDs from being filtered out upon second and later occurrences. They will instead be aggregated, and joined in the order they are processed. |
| IncludeAliasProperty | Include alias properties in addition to note properties. |
Examples
The Basic Example
I have users.csv which contains usernames and the users' departments.
I have user-mail.csv which contains usernames and the users' email addresses.
PS D:\temp> ipcsv users.csv | ft -AutoSize Username Department -------- ---------- John IT Jane HRPS D:\temp> ipcsv user-mail.csv | ft -AutoSize
Username Email -------- ----- John john@example.com Jane jane@example.com
Now I want to merge them, so I use this fabulous function and simply run this:
PS D:\temp> . .\Merge-Csv.ps1 PS D:\temp> Merge-Csv -Path users.csv, user-mail.csv -Id Username | Export-Csv -notype -enc UTF8 merged.csvPS D:\temp> ipcsv .\merged.csv | ft -AutoSize
Username Department Email -------- ---------- ----- John IT john@example.com Jane HR jane@example.com
Voìla.
A Practical Walk-through/example
Import CSV files as objects to do some work on them. The Merge-Csv function also has an -InputObject parameter that can be used instead of -Path.
PS C:\> $Csv1 = ipcsv csv-file1.csv -Delimiter ';' # semi-colon as delimiter in this one PS C:\> $Csv2 = ipcsv csv-file2.csv # comma as delimiter PS P:\> $csv1.Count 12898 PS P:\> $csv2.Count 804
You could look at the headers in Excel/notepad/whatever, but to list them using PowerShell, you can do it like this:
PS P:\> $csv2[0] | Get-Member -MemberType NoteProperty | select -exp Name Company Department DN FirstName LastLogonTimestamp LastName SamAccountName whenCreated PS P:\> $csv1[0] | Get-Member -MemberType NoteProperty | select -exp Name DEAKTIVERT DEAKTIVERTDATO ETTERNAVN FORNAVN KSTEDNAVN PAGAAVD PAGAAVDNR TITTEL USERID
So I notice one file uses "USERID", while the other uses "SamAccountName" for the ID field. Again, you could edit this in Excel or using a text editor, before the CSV import, but I demonstrate how to handle this anyway in case someone is working with custom objects from other sources than CSV files.
Here I "copy" the field "SamAccountName", and give it the name "USERID":
PS P:\> $csv2 = $csv2 | select *,@{n='USERID';e={$_.SamAccountName}}
# To anonymize I show only that the header is added, but just use
# "$Csv2[0..10]", or similar, to verify that the property is copied properly (for the first 11 objects)
PS P:\> $csv2[0] | Get-Member -MemberType NoteProperty | select -exp Name
Company
Department
DN
FirstName
LastLogonTimestamp
LastName
SamAccountName
USERID
whenCreated
Now when I merge this, I will get thousands of warnings about inconsistencies, because a lot of the users exist in $Csv1, but not in $Csv2. The syntax I use to redirect the warning stream requires PowerShell version 3 or later, so this is strongly recommended for situations like this. You can also use the "-WarningVariable SomeVariableName" parameter (in v3 as well).
I measure how long it takes. As we saw earlier, $Csv1 has almost 13,000 records, while $Csv2 has about 800. This took five minutes and 54 seconds. The PowerShell.exe process used about 608 MB RAM and the single CPU core that hosted the powershell.exe process was pegged for most of the processing time (but not all of it).
PS P:\> Measure-Command {
(Merge-Csv -InputObject $Csv1, $Csv2 -Id USERID | export-csv
-enc utf8 -notype merged.csv) 3> warnings.txt } | select TotalSeconds | ft -a
TotalSeconds
------------
354,3457868
This generated 13366 warnings:
PS P:\> (gc .\warnings.txt).Count 13366
Be aware that to redirect the warnings, you need to enclose the Merge-Csv command and possibly following pipeline in parentheses before " 3> warnings.txt".
Now to filter the merged file down to only those that have all values, I check for a "random" value I know will always be populated in $Csv1 and one for $Csv2 (different).
Here's some anonymized data from warnings.txt:
PS P:\> (gc warnings.txt | select -first 10 -skip 20) -replace "'([^']+)'", "'anon'" Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 2 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 2 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1 Identifying column entry 'anon' was not found in all CSV data objects/files. Found in object/file no.: 1
Then I filter on the "DEAKTIVERT" column from $Csv1 and the "SamAccountName" column from $Csv2 to create a report of "matches" (I should probably somehow automate this and add it to the function):
PS P:\> ipcsv .\merged.csv | where { $_.SamAccountName -and $_.DEAKTIVERT } |
Export-Csv -enc utf8 -notype merged-extract.csv
# And apparently we have 169 matches.
PS P:\> (ipcsv .\merged-extract.csv).Count
169
Handling duplicate ID entries
As of 2016-09-16, in version 1.4, I added support for duplicate IDs. The behaviour is somewhat unpredictable (except not). Elements are processed in the order in which they occur. If you have two duplicate IDs in one file/object and only one of those ID instances in the other file, the fields for the second entry will be empty/false for the file missing the second occurrence. This continues as numbers increase (2, 3, ... etc. duplicates).
Duplicate IDs are always processed in the order in which they occur, and matched with the same instance order in which they occur in the other file(s) or object(s). You need to know that this does not at all consider line numbers, just how soon (order) the duplicate(s) occur(s).
Here's a screenshot demonstration of the feature to support duplicates (somewhat) gracefully.
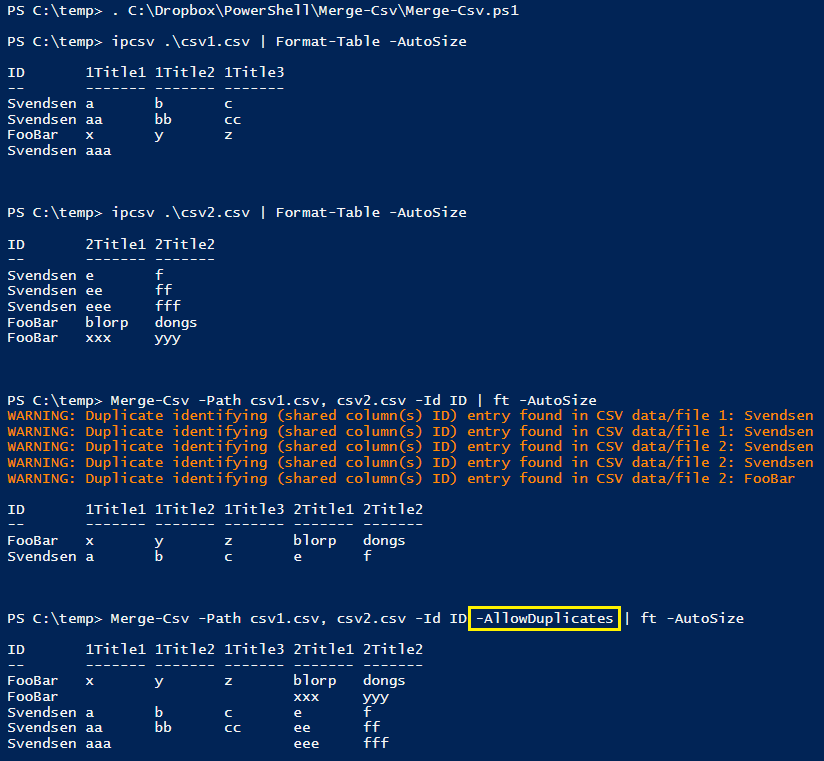
And if we add another CSV file with three "FooBar" IDs, we see that they're combined in the order they occur, as advertised.
PS C:\temp> ipcsv .\csv3.csv | ft -a ID 3Title1 -- ------- FooBar first3 Svendsen SvenData3 FooBar second3 FooBar third3PS C:\temp> Merge-Csv -Path csv1.csv, csv2.csv, csv3.csv -Id ID -AllowDuplicates | ft -AutoSize
ID 1Title1 1Title2 1Title3 2Title1 2Title2 3Title1 -- ------- ------- ------- ------- ------- ------- FooBar x y z blorp dongs first3 FooBar xxx yyy second3 FooBar third3 Svendsen a b c e f SvenData3 Svendsen aa bb cc ee ff Svendsen aaa eee fff
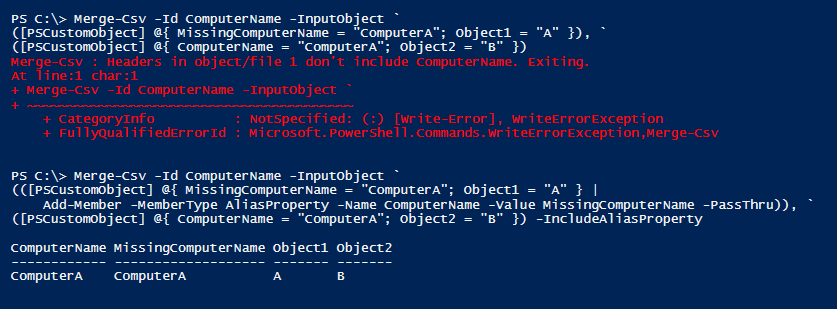
Alias Property Handling
Example of Merging Three Files
Firstly, I dot-source the Merge-Csv.ps1 file to get the Merge-Csv function into the PowerShell session. You can also use "Import-Module .\Merge-Csv.ps1".
PS D:\temp> . .\Merge-Csv.ps1
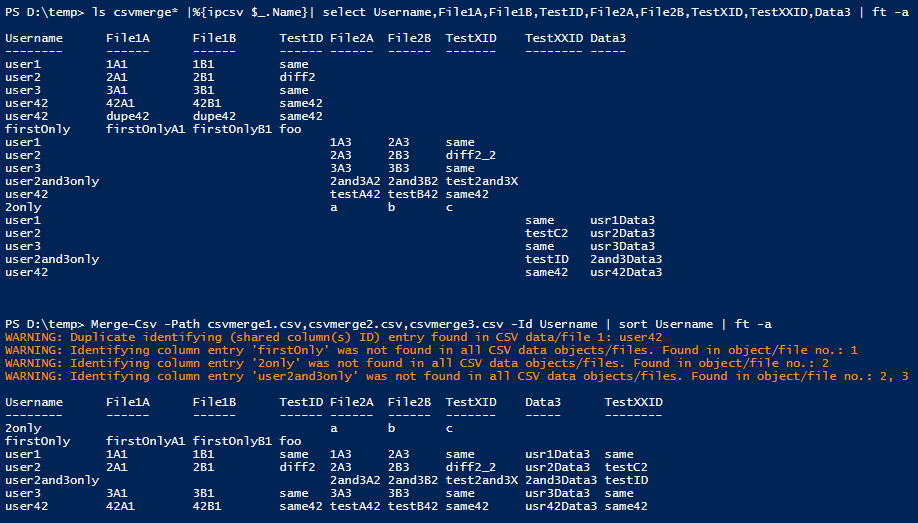
Then I display what's currently in the CSV files. You can clearly see that the "Username" column is the only one that exists in all three files, and that they have unique columns/headers. You can also see a duplicate entry in the first file (user42) and that some of the usernames exist in one or more files, but not all of them. This is reported via warning messages when I merge.
Lastly, I perform the merge, we see the warnings and the end result, which you could then pipe to Export-Csv to create the merged CSV file. You can filter columns with Select-Object and filter out rows with empty values in specific fields with Where-Object, as demonstrated briefly below.
Filtering the Merged Results
Firstly, I export to a file called merged.csv (to save screen space in these docs).
PS D:\temp> Merge-Csv -Path csvmerge1.csv, csvmerge2.csv, csvmerge3.csv -Id Username |
Sort Username | Export-Csv merged.csv
WARNING: Duplicate identifying (shared column(s) ID) entry found in CSV data/file 1: user42
WARNING: Identifying column entry 'firstOnly' was not found in all CSV data objects/files. Found in object/file no.: 1
WARNING: Identifying column entry '2only' was not found in all CSV data objects/files. Found in object/file no.: 2
WARNING: Identifying column entry 'user2and3only' was not found in all CSV data objects/files. Found in object/file no.: 2, 3
Then I use the built-in cmdlet Where-Object (or just "Where") to filter on whether the "File3" and "File1B" columns are populated by something with a true value (not $null or an empty string in this case) and display only the results for which these fields have values.
PS D:\temp> ipcsv merged.csv | Where { $_.File3 -and $_.File1B } | ft -a
Username File1A File1B TestID File2A File2B TestX File3
-------- ------ ------ ------ ------ ------ ----- -----
user1 1A1 1B1 same 1A3 2A3 same same
user2 2A1 2B1 diff2 2A3 2B3 diff2_2 testC2
user3 3A1 3B1 same 3A3 3B3 same same
user42 42A1 42B1 same42 testA42 testB42 same42 same42
Example of Merging Three Files Based on Two ID Columns
Now I change the csvmerge2.csv file's header "TestXID" to "TestID", which is shared with a column title in csvmerge1.csv. Similarly, for csvmerge3.csv, I change the title/header "TestXXID" to "TestID".
Then I attempt the same merge as before to see what happens.

Mostly out of consideration for the blind or visually impaired, I repeat it in text here:
PS D:\temp> Merge-Csv -Path csvmerge1.csv, csvmerge2.csv, csvmerge3.csv -Id Username | sort username | ft -a
Merge-Csv : Some headers are shared. Are you just looking for '@(ipcsv csv1) + @(ipcsv csv2) | Export-Csv ...'?
To remove duplicate (between the files to merge) headers from a CSV file, Import-Csv it, pass it to Select-Object, and
omit the duplicate header(s)/column(s).
Exiting.
At line:1 char:1
+ Merge-Csv -Path csvmerge1.csv, csvmerge2.csv, csvmerge3.csv -Id Userna ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [Write-Error], WriteErrorException
+ FullyQualifiedErrorId : Microsoft.PowerShell.Commands.WriteErrorException,Merge-Csv
Now, what I do is to take advantage of the fact that I allow for -Id to be an array of strings (multiple ID columns/headers), and I add "TestID", which is now shared among all the files. The CSV now looks like this:
PS D:\temp> Merge-Csv -Path csvmerge1.csv,csvmerge2.csv,csvmerge3.csv -Id Username, TestID | sort username | ft -a WARNING: Duplicate identifying (shared column(s) ID) entry found in CSV data/file 1: user42, same42 WARNING: Identifying column entry 'user2, diff2' was not found in all CSV data objects/files. Found in object/file no.: 1 WARNING: Identifying column entry 'user2and3only, testID' was not found in all CSV data objects/files. Found in object/file no.: 3 WARNING: Identifying column entry 'user2, testC2' was not found in all CSV data objects/files. Found in object/file no.: 3 WARNING: Identifying column entry '2only, c' was not found in all CSV data objects/files. Found in object/file no.: 2 WARNING: Identifying column entry 'user2and3only, test2and3X' was not found in all CSV data objects/files. Found in object/file no.: 2 WARNING: Identifying column entry 'user2, diff2_2' was not found in all CSV data objects/files. Found in object/file no.: 2 WARNING: Identifying column entry 'firstOnly, foo' was not found in all CSV data objects/files. Found in object/file no.: 1 Username TestID File1A File1B File2A File2B Data3 -------- ------ ------ ------ ------ ------ ----- 2only c a b firstOnly foo firstOnlyA1 firstOnlyB1 user1 same 1A1 1B1 1A3 2A3 usr1Data3 user2 diff2 2A1 2B1 user2 diff2_2 2A3 2B3 user2 testC2 usr2Data3 user2and3only testID 2and3Data3 user2and3only test2and3X 2and3A2 2and3B2 user3 same 3A1 3B1 3A3 3B3 usr3Data3 user42 same42 42A1 42B1 testA42 testB42 usr42Data3
Mostly out of consideration for the sighted among us, I also provide a screenshot of the same (I'm funny, ain't I?).
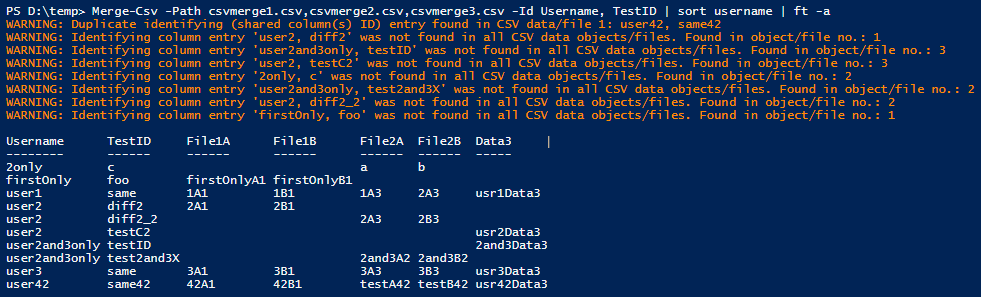
Observe the warnings which are now about the combination of the two fields (just simple string comparisons using the values joined with the default -Separator string, which can be changed if needed).
Powershell Windows CSVBlog articles in alphabetical order
A
- A Look at the KLP AksjeNorden Index Mutual Fund
- A primitive hex version of the seq gnu utility, written in perl
- Accessing the Bing Search API v5 using PowerShell
- Accessing the Google Custom Search API using PowerShell
- Active directory password expiration notification
- Aksje-, fonds- og ETF-utbytterapportgenerator for Nordnet-transaksjonslogg
- Ascii art characters powershell script
- Automatically delete old IIS logs with PowerShell
C
- Calculate and enumerate subnets with PSipcalc
- Calculate the trend for financial products based on close rates
- Check for open TCP ports using PowerShell
- Check if an AD user exists with Get-ADUser
- Check when servers were last patched with Windows Update via COM or WSUS
- Compiling or packaging an executable from perl code on windows
- Convert between Windows and Unix epoch with Python and Perl
- Convert file encoding using linux and iconv
- Convert from most encodings to utf8 with powershell
- ConvertTo-Json for PowerShell version 2
- Create cryptographically secure and pseudorandom data with PowerShell
- Crypto is here - and it is not going away
- Crypto logo analysis ftw
D
G
- Get rid of Psychology in the Stock Markets
- Get Folder Size with PowerShell, Blazingly Fast
- Get Linux disk space report in PowerShell
- Get-Weather cmdlet for PowerShell, using the OpenWeatherMap API
- Get-wmiobject wrapper
- Getting computer information using powershell
- Getting computer models in a domain using Powershell
- Getting computer names from AD using Powershell
- Getting usernames from active directory with powershell
- Gnu seq on steroids with hex support and descending ranges
- Gullpriser hos Gullbanken mot spotprisen til gull
H
- Have PowerShell trigger an action when CPU or memory usage reaches certain values
- Historical view of the SnP 500 Index since 1927, when corona is rampant in mid-March 2020
- How Many Bitcoins (BTC) Are Lost
- How many people own 1 full BTC
- How to check perl module version
- How to list all AD computer object properties
- Hva det innebærer at særkravet for lån til sekundærbolig bortfaller
I
L
M
P
- Parse openssl certificate date output into .NET DateTime objects
- Parse PsLoggedOn.exe Output with PowerShell
- Parse schtasks.exe Output with PowerShell
- Perl on windows
- Port scan subnets with PSnmap for PowerShell
- PowerShell Relative Strength Index (RSI) Calculator
- PowerShell .NET regex to validate IPv6 address (RFC-compliant)
- PowerShell benchmarking module built around Measure-Command
- Powershell change the wmi timeout value
- PowerShell check if file exists
- Powershell check if folder exists
- PowerShell Cmdlet for Splitting an Array
- PowerShell Executables File System Locations
- PowerShell foreach loops and ForEach-Object
- PowerShell Get-MountPointData Cmdlet
- PowerShell Java Auto-Update Script
- Powershell multi-line comments
- Powershell prompt for password convert securestring to plain text
- Powershell psexec wrapper
- PowerShell regex to accurately match IPv4 address (0-255 only)
- Powershell regular expressions
- Powershell split operator
- Powershell vs perl at text processing
- PS2CMD - embed PowerShell code in a batch file
R
- Recursively Remove Empty Folders, using PowerShell
- Remote control mom via PowerShell and TeamViewer
- Remove empty elements from an array in PowerShell
- Remove first or last n characters from a string in PowerShell
- Rename unix utility - windows port
- Renaming files using PowerShell
- Running perl one-liners and scripts from powershell
S
- Sammenlign gullpriser og sølvpriser hos norske forhandlere av edelmetall
- Self-contained batch file with perl code
- Silver - The Underrated Investment
- Simple Morningstar Fund Report Script
- Sølv - den undervurderte investeringen
- Sort a list of computers by domain first and then name, using PowerShell
- Sort strings with numbers more humanely in PowerShell
- Sorting in ascending and descending order simultaneously in PowerShell
- Spar en slant med en optimalisert kredittkortportefølje
- Spre finansiell risiko på en skattesmart måte med flere Aksjesparekontoer
- SSH from PowerShell using the SSH.NET library
- SSH-Sessions Add-on with SCP SFTP Support
- Static Mutual Fund Portfolio the Last 2 Years Up 43 Percent
- STOXR - Currency Conversion Software - Open Exchange Rates API