
Jump to page sections
- Regular Expressions in PowerShell
- Recommended Regular Expressions Book
- Built-in Operators and cmdlets
- Examples
- Example - The -match Operator
- The -match Operator on Collections/Arrays
- Example - The -NotMatch Operator
- Example - The -replace Operator
- The -replace Operator on Collections/Arrays
- Example - Replace With Captures
- Example - Named Captures
- Example - The -split Operator
- Example - Select-String
- Example - Log Parsing
- Example - The -like Operator
- Example - The -NotLike Operator
- Mode Modifiers
- Regex Class
- Class Methods
- Match
- Matches
- Replace
- Escaping and Unescaping Regexp Meta-characters
- Match Evaluator
Regular Expressions in PowerShell
A regular expression is a sequence of logically combined characters and meta characters (characters with special meaning) that, according to parsing rules in the regexp engine, describes text which matches a certain pattern. I will assume you are familiar with both PowerShell and regular expressions and want to know how to use the latter in PowerShell. I have realized a lot of people don't know regexp syntax/logic. There are quite a few resources on this on the web, but I will look into writing a generic tutorial that will cover some common cases and pitfalls. I have a Perl background myself, so I will make a few comparisons.
This Python doc about regex seems like a good place to learn about basic regex syntax (which will work the same in .NET/PowerShell for the most part).
PowerShell uses the .NET regexp engine. Basically, I've found its syntax and behaviour to overlap with Perl's and Python's in most respects.Everything in this article should work in PowerShell version 2 and up.
Recommended Regular Expressions Book
Built-in Operators and cmdlets
Examples
Example - The -match Operator
This will extract the first occurrence of digits (0-9) in sequence in a string. Rather than "\d", you could also have used the character class "[0-9]" - I am not aware of a locale with "other digits" included in "\d". The built-in classes like \d and \w can respect locale. By default the \w class in .NET uses the Unicode definition of a "word character", so it includes, among other things, accented and Scandinavian alphabet characters.

If you have "surrounding" regexp parts around the captured part, they will be included in $Matches[0] which holds the complete regexp match. Below you will see that "abc" is now included in $Matches[0], because I added "[a-z]+", which means "match one or more characters from a to z, inclusively, match as many as you can". Read more about regexp character classes here. $Matches[1] is still "123".
PS E:\> 'abc123def456' -match '[a-z]+(\d+)' | Out-Null; $Matches[0,1] abc123 123
The result of -match will normally either be True or False, but this is suppressed here by piping to Out-Null. Note that if you use -match in an if statement, you should not pipe to Out-Null, as demonstrated below. This one bit me the first time around.
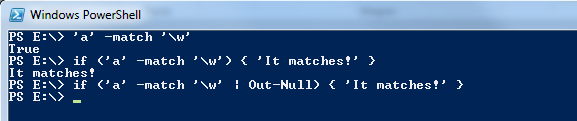
The expression in an if statement normally isn't output, and if you pipe to Out-Null, the expression that will be evaluated is apparently indeed $null (which is considered false by the if statement):
PS E:\> if ((1 | out-null) -eq $null) { 'yes' }
yes
PS E:\> if ((1 | out-null) -ne $null) { 'yes' }
PS E:\>
If you use a double-quoted string around the regexp part, variables will be interpolated. So if you, say, wanted to get an integer ("\d+" and "[0-9]+" are normally equivalent), after a space, after a string you have stored in a variable, you could do it like I demonstrate below. I would normally use "\s+" or "\s*" rather than a literal space, as it's more robust, but sometimes you want to be precise, so it depends on your requirements. In this case, it's just for readability.
PS C:\> $GetThis = 'SecretCode' PS C:\> 'foo bar baz SecretCode 42 boo bam' -match "$GetThis ([0-9]+)" True PS C:\> $matches Name Value ---- ----- 1 42 0 SecretCode 42
The -match Operator on Collections/Arrays
PS D:\> @('0a', '0b', '0x') -match '([\da-f]{2})'
0a
0b
PS D:\> $Matches
PS D:\>
Here we see that it evaluates to true when there's a match and false when there isn't.
PS D:\temp> if ( @('0a', '0b', '0x') -match '[\da-f]{2}' ) {
'match'
} else { 'no match' }
match
PS D:\temp> if (@('0y', '0z', '0x') -match '[\da-f]{2}') {
'match'
} else { 'no match' }
no match
Example - The -NotMatch Operator
PS C:\> 'fo', 'fooooo', 'foob', 'fooo', 'ding' |
Where-Object {$_ -NotMatch '^fo+$'}
foob
ding
Read more about the PowerShell Where-Object cmdlet here.
Example - The -replace Operator
I have not found a way to make -replace not replace all occurrences, so it's equivalent to s///g in Perl by default. You can anchor to target the first and last match as demonstrated below. Also see the regex class method "replace" description for, among other things, a way to replace only once (the specified number of times).
Note: The regexp meta character "\A" means "really the start of the string", and matches only once, even if you specify the ''MultiLine'' regexp option, whereas "^" will match at the start of every line with the ''MultiLine'' option. The same respectively applies to "\z" and "$", except they mean the end of the string. In the cases where you only have one line, they are equivalent. So you could have used "\A" instead of "^" in the example below, and "\z" instead of "$". I used the most commonly known variants.
PS E:\> 'aaaa' -replace 'a', 'b'
bbbb
PS E:\> 'aaaa' -replace '^a', 'b'
baaa
PS E:\> 'aaaa' -replace 'a$', 'b'
aaab
# A little trick to target the last "a". More on this later in the capture/replace parts:
PS E:\> 'aaaa' -replace '(.*)a', '${1}b'
aaab
"$" also matches after a newline before the end of the line, whereas "\z" does not, as demonstrated here:
PS C:\> "bergen`n" -imatch 'gen$' True PS C:\> "bergen`n" -imatch 'gen\z' False PS C:\> 'bergen' -imatch 'gen\z' True
The -replace Operator on Collections/Arrays
PS C:\temp> $Array = @('host1.svendsentech.no', 'host2.svendsentech.no', 'host3.svendsentech.no')
PS C:\temp> $Array -replace '\.svendsentech\.no$'
host1
host2
host3
And here's an example of the regex not matching so the strings are unchanged.
PS C:\temp> $Array -replace 'doesNotMatch', 'something' host1.svendsentech.no host2.svendsentech.no host3.svendsentech.no
Example - Replace With Captures
Here are a few quick examples:
PS E:\> 'Smith, John' -ireplace '([a-z]+)\s*,\s+([a-z]+)', '$2 $1' John Smith PS E:\> 'Smith, John' -ireplace '(\w+), (\w+)', "`$2 `$1" John Smith PS E:\> # The following, with double quotes, does not work as you wish. PS E:\> 'Smith, John' -ireplace '(\w+), (\w+)', "$2 $1" PS E:\>
If you find yourself thinking you'd like to process $1, $2, $3 and so on, "on the fly", you might want to check out the match evaluator part below.
Example - Named Captures
.NET supports named captures, which means you can use a name for a captured group rather than a number. You can mix and match and any non-named capture group will be numbered from left to right. To name a capture, use either the (?<name>regex) or (?'name'regex) syntax where name is the name of the capture group. To reference it in a -replace part, use a single-quoted string and the syntax ${name}.
If you are using a double-quoted string for the regular expression, you can use either syntax as described above, but if you are using a single-quoted string, like I usually do, you have to use doubled-up single quotes if you want to use the (?'name'regex) syntax, like this:PS C:\> 'foo bar baz' -match '(?''test''\w+)' | Out-Null; $matches['test'] foo
Here follow some examples.
Notice how the content of the first capture group is placed in $matches[1], the named capture is in $matches['named'] and the second capture group, although being the third group, is in ''$matches[2]'' since the named capture is stored using a name.PS C:\> 'first namedcaptureword second' -match '(\w+) (?<named>\w+) (\w+)'; $matches True Name Value ---- ----- named namedcaptureword 2 second 1 first 0 first namedcaptureword second
Index a single named capture by name like this:
PS C:\> $matches['named'] namedcaptureword
Shuffle two occurences of non-whitespace sequences separated by a space:
PS C:\> [regex]$regex = '\A(?<putlast>\S+) (?<putfirst>\S+)\z'
PS C:\> 'second first' -ireplace $regex, '${putfirst} ${putlast}'
first second
Example - The -split Operator
The -split operator also takes a regular expression, so to, say, split on a number, you could do it like this:
PS E:\> 'first1second2third3fourth' -split '\d' first second third fourth
With Perl, you could do it like this (read more about Perl from PowerShell here):
PS E:\> perl -wle "print join qq(\n), split /\d/, 'first1second2third3fourth';" first second third fourth
Example - Select-String
In PowerShell v3 you also have a -Tail parameter for getting the last specified number of lines. With PowerShell v1 and v2, you can pipe to Select-Object and use either the -first or -last parameter, and specify the desired number of lines to display. Example: Get-Content usernames.txt | Select-Object -last 15'. You can also just type Select rather than Select-Object, as it's aliased (type "alias select" at the prompt). But in scripts meant for reuse, it is strongly encouraged to use the full form/name of the cmdlet, not an alias.
Here are a few quick examples, based on a file which you can guess the contents of.PS E:\> Select-String '[aeiouy]' .\alphabet.txt alphabet.txt:1:a alphabet.txt:5:e alphabet.txt:9:i alphabet.txt:15:o alphabet.txt:21:u alphabet.txt:25:y PS E:\> Get-Content .\alphabet.txt | Select-String '[aeiouy]' a e i o u y PS E:\> Get-Content .\alphabet.txt | Select-String 'i' -Context 3 f g h > i j k l
Using two values for the -Context parameter:
PS D:\> $Alphabet = 97..122 |
%{ [string][char]$_ }
PS D:\> $Alphabet |
Select-String -Context 0,3 i
> i
j
k
l
To get only the preceding or following line(s) when using the -Context parameter, you can do it like I demonstrate below. A trick I picked up from Dave Wyatt on http://powershell.org. Simply omit "$_.Matches[0].Value" to have only the post-context stuff.
PS D:\temp> $alphabet |
Select-String 'd' -Context 1 |
% {$_.Matches[0].Value, $_.Context.PostContext[0]}
d
e
Get the two next lines; remember to pass "2" to context - and to index into the array properly with "0,1" (or omit the indexing):
PS D:\temp> $alphabet |
Select-String 'd' -Context 2 |
% {$_.Matches[0].Value, $_.Context.PostContext[0,1]}
d
e
f
PS D:\temp> $alphabet |
Select-String 'd' -Context 3 |
% { $_.Context.PostContext }
e
f
g
Here's a way to get the preceding line and the match:
PS D:\temp> $alphabet |
Select-String 'd' -Context 1 |
% {$_.Context.PreContext[0], $_.Matches[0].Value}
c
d
If you want a boolean value (true or false) for whether there's a match, you can use the -Quiet parameter:
PS C:\> 'hello' |
Select-String -Quiet 'HellO'
True
Example - Log Parsing
001 | ERROR: This is the first error ::: Code: 400 002 | WARNING: Excess cheese. ::: Code: 200 003 | ErrOR: This is the second error. ::: Code: 401 004 | INFO: LoL ::: Code: 5
There are many ways to attack this. Here I demonstrate something halfway sane, where the aim is to have a highly flexible and broadly matching regexp. The regexp logic for the regexp in the code field below is as described in the table below that field.
^\s*\d+\s*\|\s*ERROR:\s*(.+):::\s*Code:\s*(\d+)
| Anchor at the beginning of the string | ^ | Beginning of string, matching after every newline with the MultiLine regexp option. |
| Possibly whitespace | \s* | Zero or more whitespace characters, match as many as you can; always matches! |
| A sequence of digits | \d+ | One or more digits, match as many as you can, greedily; so-called greedy matching. |
| Possibly whitespace | \s* | Zero or more whitespace characters, match as many as you can; always matches! |
| A literal pipe character | \| | Escaped pipe character, making it a literal pipe - otherwise it's effectively an ''OR''. Escape using a backslash, not the PowerShell escape backtick character. |
| Possibly whitespace | \s* | Zero or more whitespace characters, match as many as you can; always matches! |
| The string "ERROR:" | ERROR: | The literal string "ERROR:", including the literal ":". |
| Possibly whitespace | \s* | Zero or more whitespace characters, match as many as you can; always matches! |
| Capture all non-newline characters | (.+)::: | Capture the error message by getting everything until you hit the literal string ":::". Technically, .+ goes to the end and then "backtracks" until it matches ":::", I assume you indeed want the greedy version and to get the last match if there's an instance of ":::" in the error message. Use .+? for non-greedy matching. |
| Possibly whitespace | \s* | Zero or more whitespace characters, match as many as you can; always matches! |
| The string "Code:" | Code: | The literal string "Code:" including the literal ":". |
| Possibly whitespace | \s* | Zero or more whitespace characters, match as many as you can; always matches! |
| Capture a sequence of digits making up the error code | (\d+) | One or more digits, match as many as you can, greedily; so-called greedy matching. |
The first match is stripped of trailing whitespace after the match, handily using ''-replace''. This is difficult to avoid without using "\s+" before ":::" and thus making the regexp slightly less flexible.
Most regexp engines will match the first occurrence, even if it is not at the beginning of the string (you don't need a complete match) as the .NET and Perl engines do, so you could omit the part before the escaped pipe. However, it adds some data integrity validation, by making sure the strings matched are in an expected format. The escape character in Powershell is a backtick (`), not a backslash (\), ''but in regular expressions, you escape using a backslash''.You could also have added something like "\s*\z" or "\s*$" at the end (they will be entirely equivalent in that case, because \s matches newlines), but it allows you to capture some potentially malformed data without it. It depends on the requirements when you design the regular expression; sometimes you want maximum data validation, sometimes you want it as broadly matching or inclusive as possible, and sometimes something in between.
PS E:\> Get-Content .\logfile.log |
%{ if ($_ -imatch '^\d+\s*\|\s*ERROR:\s*(.+):::\s+Code:\s+(\d+)') {
'Error string: '+ ($matches[1] -replace '\s+$', '') + ' | Code: ' + $matches[2]
} }
Error string: This is the first error | Code: 400
Error string: This is the second error. | Code: 401
With Perl you could do it like this, using the same regular expression. Notice that I added the /i flag to the regexp for case-insensitivity. The "m" in "m//" can be omitted when using slashes as delimiters, as they are the default in Perl and this has been special-cased. Read more about Perl from PowerShell here.
PS E:\> perl -nwle 'if (m/^\s*\d+\s*\|\s*ERROR:\s*(.+):::\s*Code:\s*(\d+)/i) { ($errmsg, $code) = ($1, $2); $errmsg =~ s/\s+$//; print qq(Error string: $errmsg | Code: $code) }' .\logfile.log
Error string: This is the first error | Code: 400
Error string: This is the second error. | Code: 401
Example - The -like Operator
The special characters the -like operator recognizes are described in the following table:
| ? | One instance of any character. |
| * | Zero or more instances of any character. |
| [<Start>-<End>(<Start>-<End>)] | Range of numbers or characters. Multiple ranges are supported. |
So to see if a string starts with a hex digit (followed by anything or nothing), you could use this:
PS C:\> 'deadbeef' -like '[a-f0-9]*' True PS C:\> 'xdeadbeef' -like '[a-f0-9]*' False
To make sure a string starts with a letter between a-z and is followed by exactly one other character that can be anything, you could use:
PS C:\> 'v2' -like '[a-z]?' True PS C:\> 'v' -like '[a-z]?' False PS C:\> 'v22' -like '[a-z]?' False
Example - The -NotLike Operator
PS C:\> 'fo', 'dinner', 'foob', 'fooo', 'ding' |
Where-Object {$_ -NotLike 'fo*'}
dinner
ding
Read more about the PowerShell Where-Object cmdlet here.
Mode Modifiers
You might know mode modifiers from other languages, like "i" (case-insensitivity), "m" (multi-line, makes "^" and "$" match respectively at the beginning and end of every line) and "s" (makes "." also match newlines). "g" for global matching, such as used in Perl, is gloriously missing, and instead you have varying default behaviour that may or may not be desirable.
With the [regex]::match() and [regex]::matches() methods you can match once or globally. -match matches once by default. Most of the time, you can just use -match rather than [regex]::match().I also describe a way of only replacing the specified number of times below, in the ''replace'' section. So you could use "1" for replacing only once, which is the same as not using global matching in other languages. So, actually, with .NET there is a way to have even more control than by using the optional "g" flag, where its presence means "replace all occurrences" and its absence means "replace first occurrence only" (a trick to match the last occurrence instead, is to add ".*" in front of the part to replace, because that will go to the end of the string and then "backtrack" until it finds a successful match for the remainder of the regular expression). Anchoring can also be used, as mentioned in the part about the -replace operator.
The modifiers, or regexp options, are of the type System.Text.RegularExpressions.RegexOptions as described in this Microsoft article. You can also inspect them with this command:[System.Text.RegularExpressions.RegexOptions] | Get-Member -Static -Type Property
Mode modifiers override other passed options. The effect on case-sensitivity when using the operators -imatch or -cmatch is overridden by the modifiers "(?i)" and "(?-i)", which accordingly enable and disable case-insensitivity. You can use mode modifiers "inline" in the regular expression, which you compile, store in a variable and subsequently use - or you can specify it directly.
Here is a quick demonstration:PS E:\> $regex = [regex]'(?-i)A' PS E:\> 'A' -imatch $regex True PS E:\> 'a' -imatch $regex False PS E:\> 'a' -cmatch '(?i)A' True PS E:\> 'a' -imatch '(?-i)A' False
Regex Class
Class Methods
Match
An elegant way to retrieve the result from a regex with no surrounding regex parts would be the case below, that demonstrates one case where you might want it over the -match operator.
PS C:\> ([regex]'\d{8}').Match('abc12345678def').Value
12345678
# Some might think that is cleaner than this:
PS C:\> [void] ('abc12345678def' -match '\d{8}'); $Matches[0]
12345678
# or this:
PS C:\> if ('abc12345678def' -match '\d{8}') {
$Matches[0]
}
Matches
PS E:\> $str = "a123`nb456`nc789"
PS E:\> [regex]::matches($str, '^(\w)') |
% {$_.Value}
a
PS E:\> [regex]::matches($str, '^(\w)', 'MultiLine') |
ForEach-Object {$_.Value}
a
b
c
PS E:\> [regex]::matches($str, '(?-m)^(\w)', 'MultiLine') |
ForEach {$_.Value}
a
PS E:\>
Unlike the -match operator, [regex]::matches matches "globally" by default, like you would with m//g in Perl. As demonstrated below. For a single match, you can use [regex]::match, or just use the -match operator.
PS E:\> [regex]::matches('abc', '(\w)') |
% { $_.Value }
a
b
c
Multiple regexp options need to be specified as an array, as demonstrated below. The syntax is '''@('Option1', 'Option2', [...])'''.
PS C:\> [regex]::matches("a1`nb2`nc3", '^([A-Z])\d',
@('MultiLine', 'Ignorecase')) |
% { $_.Value }
a1
b2
c3
PS C:\> [regex]::matches("a1`nb2`nc3", '^([A-Z])\d', @(
'Ignorecase')) | % { $_.Value }
a1
PS C:\> [regex]::matches("a1`nb2`nc3", '^([A-Z])\d') |
% { $_.Value }
PS C:\>
To get the captured group, you need to reference the returned ''System.Text.RegularExpressions.Match'' object's "Groups" property and index into the array. The first element will be the whole match, the second will be the first capture group, the third will be the second capture group, and so on. Basically, you can index into the array like using $1, $2, etc., meaning $_.Groups[1].Value is equivalent to $1. $_.Value will be the same as $_.Groups[0].Value.
Below is a demonstration of getting the first and second capture group.
PS E:\> [regex]::matches("a1`nb2`nc3",
'^([A-Z])(\d)',
@('MultiLine', 'Ignorecase')) |
% { $_.Groups[1].Value }
a
b
c
PS E:\> [regex]::matches("a1`nb2`nc3",
'^([A-Z])(\d)',
@('MultiLine', 'Ignorecase')) |
% { $_.Groups[2].Value }
1
2
3
Replace
Here's a capture and replace.
PS E:\> [regex]::replace('second first',
'([a-z]+) ([a-z]+)',
'$2 $1')
first second
Here is a demonstration of how it replaces globally (as many times as it matches), like s///g in Perl.
PS E:\> [regex]::replace('second first', '(?[aeiouy])', '-${vowel}')
s-ec-ond f-irst
To replace only once (or the specified number of times), you need to instantiate a regex object and call the Replace() method on it. Example that replaces three times:
PS E:\> [regex] $regex = '[a-z]'
PS E:\> $regex.Replace('abcde', 'X', 3)
XXXde
Here "abcde" is the input string, "X" is the replacement string and "3" is the number of times to replace. The regexp is "[a-z]".
To run it as a one-liner, you could do it like this:
PS C:\> ([regex]'\d').Replace('12345', '#', 2)
##345
Notice that unlike -replace and -ireplace, [regex]::replace is case-sensitive by default. You can add the same regexp options as for [[Powershell_regular_expressions#Matches|[regex]::matches]], including the "IgnoreCase" flag.
PS E:\> [regex]::replace('sEcond fIrst',
'(?[aeiouy])',
'-${vowel}')
sEc-ond fIrst
PS E:\> [regex]::replace('sEcond fIrst',
'(?[aeiouy])',
'-${vowel}', 'IgnoreCase')
s-Ec-ond f-Irst
As with [regex]::Matches() you specify multiple regexp options in an array in the format @('Option1', 'Option2') and so on. Here's a demonstration where we see both the options are used:
PS C:\> [regex]::replace("a1`nb2`nc3",
'^([A-Z])\d',
'${1}X',
@('MultiLine', 'IgnoreCase'))
aX
bX
cX
Escaping and Unescaping Regexp Meta-characters
In this example, I have an array of users, $Users, which contains users in the form <DOMAIN>\<USERNAME>. Now, if you wanted to see if another value in an array you're looping over exists in this array, you could probably use the -Contains operator (or -In from v3 up), but if you need or want a regexp for some reason, you will probably find yourself constructing something like this:
^(?:option1|option2|option3)$
The problem you will run into in this case, is that the domain\user structure contains a backslash, which means that when you pass it to the right-hand side of the -match (or -replace) operator, it will be interpreted as a special sequence. If the username starts with "s", you will get "\s", which is whitespace, and not what you want. If the escape sequence isn't recognized/valid, you will get errors. To work around this, you can use the [regex]::Escape() method.
PS C:\> $Users = @('domain\foo', 'domain\bar')
PS C:\> $Users
domain\foo
domain\bar
PS C:\> [regex] $UserRegex = '^(?:' + ( ($Users | %{ [regex]::Escape($_) }) -join '|') + ')$'
# And the finished regexp looks like this:
PS C:\> $UserRegex.ToString()
^(?:domain\\foo|domain\\bar)$
# Now match
PS C:\> 'domain\hello' -imatch $UserRegex
False
PS C:\> 'domain\foo' -imatch $UserRegex
True
PS C:\> 'domain\bar' -imatch $UserRegex
True
PS C:\> 'domain\barista' -imatch $UserRegex
False
Match Evaluator
I can add that $args[1] will be empty (at least it has been during my tests) and that $args[0] contains an object of the type [System.Text.RegularExpressions.Match] as described in this Microsoft article. You can assign it to a variable in the script block for later inspection with Get-Member (alias gm) and the likes.
PS E:\> $counter = 0
PS E:\> [regex]::replace($alphabet,
'[aeiouy]',
{ ' ' + $args[0].Value.ToUpper() + ++$counter + ' ' })
A1 bcd E2 fgh I3 jklmn O4 pqrst U5 vwx Y6 z
You pass in (multiple) regexp options after the script block, as for the matches() and replace() methods. Demonstrated here:
PS E:\temp> $counter = 0
PS E:\temp> [regex]::replace("ab`nef`nij",
'^[AEIOUY]',
{ $args[0].Value.ToUpper() + ++$counter + ' ' },
@('IgnoreCase', 'MultiLine'))
A1 b
E2 f
I3 j
For the heck of it, I'm adding a Perl version that you can run from PowerShell (does not work from cmd.exe due to quoting differences, and of course "$alphabet" isn't very useful in cmd.exe):
PS E:\> $alphabet | perl -pe 's/([aeiouy])/q( ) . uc $1 . ++$counter . q( )/ige' A1 bcd E2 fgh I3 jklmn O4 pqrst U5 vwx Y6 z
Read more about Perl from PowerShell here. And here's a cmd.exe version anyway:
C:\>perl -e "print a..z" | perl -pe "s/([aeiouy])/q( ) . uc $1 . ++$counter . q( )/ige" A1 bcd E2 fgh I3 jklmn O4 pqrst U5 vwx Y6 z
I came across a scenario where this feature seems tremendously useful, namely in decoding HTML entities to characters in a string. I had to add a space between the "&" and the "#" in order for the character not to be displayed as a quote here in the wiki. In the real string, there are no such spaces...
PS C:\> Add-Type -AssemblyName System.Web
PS C:\> [System.Web.HttpUtility]::HtmlDecode('& #x22;')
"
PS C:\> $String = "Here's a & #x22;quoted& #x22; word"
PS C:\> $DecodedString = [regex]::Replace($String,
'&[^;]+;', { [Web.HttpUtility]::HtmlDecode($args[0].Value) })
PS C:\> $DecodedString
Here's a "quoted" word
PS C:\>
Powershell
Perl
Regex
Windows
Blog articles in alphabetical order
A
- A Look at the KLP AksjeNorden Index Mutual Fund
- A primitive hex version of the seq gnu utility, written in perl
- Accessing the Bing Search API v5 using PowerShell
- Accessing the Google Custom Search API using PowerShell
- Active directory password expiration notification
- Aksje-, fonds- og ETF-utbytterapportgenerator for Nordnet-transaksjonslogg
- Ascii art characters powershell script
- Automatically delete old IIS logs with PowerShell
C
- Calculate and enumerate subnets with PSipcalc
- Calculate the trend for financial products based on close rates
- Check for open TCP ports using PowerShell
- Check if an AD user exists with Get-ADUser
- Check when servers were last patched with Windows Update via COM or WSUS
- Compiling or packaging an executable from perl code on windows
- Convert between Windows and Unix epoch with Python and Perl
- Convert file encoding using linux and iconv
- Convert from most encodings to utf8 with powershell
- ConvertTo-Json for PowerShell version 2
- Create cryptographically secure and pseudorandom data with PowerShell
- Crypto is here - and it is not going away
- Crypto logo analysis ftw
D
G
- Get rid of Psychology in the Stock Markets
- Get Folder Size with PowerShell, Blazingly Fast
- Get Linux disk space report in PowerShell
- Get-Weather cmdlet for PowerShell, using the OpenWeatherMap API
- Get-wmiobject wrapper
- Getting computer information using powershell
- Getting computer models in a domain using Powershell
- Getting computer names from AD using Powershell
- Getting usernames from active directory with powershell
- Gnu seq on steroids with hex support and descending ranges
- Gullpriser hos Gullbanken mot spotprisen til gull
H
- Have PowerShell trigger an action when CPU or memory usage reaches certain values
- Historical view of the SnP 500 Index since 1927, when corona is rampant in mid-March 2020
- How Many Bitcoins (BTC) Are Lost
- How many people own 1 full BTC
- How to check perl module version
- How to list all AD computer object properties
- Hva det innebærer at særkravet for lån til sekundærbolig bortfaller
I
L
M
P
- Parse openssl certificate date output into .NET DateTime objects
- Parse PsLoggedOn.exe Output with PowerShell
- Parse schtasks.exe Output with PowerShell
- Perl on windows
- Port scan subnets with PSnmap for PowerShell
- PowerShell Relative Strength Index (RSI) Calculator
- PowerShell .NET regex to validate IPv6 address (RFC-compliant)
- PowerShell benchmarking module built around Measure-Command
- Powershell change the wmi timeout value
- PowerShell check if file exists
- Powershell check if folder exists
- PowerShell Cmdlet for Splitting an Array
- PowerShell Executables File System Locations
- PowerShell foreach loops and ForEach-Object
- PowerShell Get-MountPointData Cmdlet
- PowerShell Java Auto-Update Script
- Powershell multi-line comments
- Powershell prompt for password convert securestring to plain text
- Powershell psexec wrapper
- PowerShell regex to accurately match IPv4 address (0-255 only)
- Powershell regular expressions
- Powershell split operator
- Powershell vs perl at text processing
- PS2CMD - embed PowerShell code in a batch file
R
- Recursively Remove Empty Folders, using PowerShell
- Remote control mom via PowerShell and TeamViewer
- Remove empty elements from an array in PowerShell
- Remove first or last n characters from a string in PowerShell
- Rename unix utility - windows port
- Renaming files using PowerShell
- Running perl one-liners and scripts from powershell
S
- Sammenlign gullpriser og sølvpriser hos norske forhandlere av edelmetall
- Self-contained batch file with perl code
- Silver - The Underrated Investment
- Simple Morningstar Fund Report Script
- Sølv - den undervurderte investeringen
- Sort a list of computers by domain first and then name, using PowerShell
- Sort strings with numbers more humanely in PowerShell
- Sorting in ascending and descending order simultaneously in PowerShell
- Spar en slant med en optimalisert kredittkortportefølje
- Spre finansiell risiko på en skattesmart måte med flere Aksjesparekontoer
- SSH from PowerShell using the SSH.NET library
- SSH-Sessions Add-on with SCP SFTP Support
- Static Mutual Fund Portfolio the Last 2 Years Up 43 Percent
- STOXR - Currency Conversion Software - Open Exchange Rates API