
Jump to page sections
- Scenario
- Listing the cmdlet Set-Content's Supported Encodings
- Solution
- Create Problematic Data
- Verify It Displays Incorrectly
- Convert To UTF-8 and Verify It Displays Correctly
- Additional Information and Avoiding a Temporary File
- Screenshot Example
This article was originally written some time between 2011 and 2015. Last update: 2022-01-26.
Scenario
If you have an ANSI-encoded file, or a file encoded using some other (supported) encoding, and want to convert it to UTF-8 (or another supported encoding), this article is for you. I ran into this when working with exported data from Excel which was in latin1/ISO8859-1 by default, and I couldn't find a way to specify UTF-8 in Excel.
The problem occurred when I wanted to work on the CSV file using the PowerShell cmdlet Import-Csv, which, as far as I can tell, doesn't work correctly with latin1-encoded files exported from Excel or ANSI files created with notepad - if they contain non-US characters. 2022-01-26: It's a known bug that has probably been fixed in PowerShell v7. It seems still present in PowerShell 5.1. The bug occurs when the file is missing the UTF-8 BOM (more on that below). The bug was submitted to Microsoft Connect years ago here.
A command you may be looking for is Set-Content. Type "Get-Help Set-Content -Online" at a PowerShell prompt to read the help text, and see the example below.
Also see the part about using Get-Content file.csv | ConvertFrom-Csv.
Click here for an article on how to convert using iconv on Linux.Internally in PowerShell, a string is a sequence of 16-bit Unicode characters (often called a Unicode code point or Unicode scalar value). It's implemented directly using the .NET System.String type, which is a reference type (read more about that in my deep copying article).
A string can be arbitrarily long (computer memory and physics as we currently understand it allowing) and it is immutable, meaning it cannot be changed without creating an entirely new altered version/"copy" of the string.Listing the cmdlet Set-Content's Supported Encodings
PS C:\> 'foo' | Set-Content -Encoding whatever
Set-Content : Cannot bind parameter 'Encoding'. Cannot convert value "whatever" to type "Microsoft.PowerShell.Commands.
FileSystemCmdletProviderEncoding" due to invalid enumeration values. Specify one of the following enumeration values an
d try again. The possible enumeration values are "Unknown, String, Unicode, Byte, BigEndianUnicode, UTF8, UTF7, Ascii".
At line:1 char:30
+ 'foo' | Set-Content -Encoding <<<< whatever
+ CategoryInfo : InvalidArgument: (:) [Set-Content], ParameterBindingException
+ FullyQualifiedErrorId : CannotConvertArgumentNoMessage,Microsoft.PowerShell.Commands.SetContentCommand
Notice the part with the possible enumeration values:
- Unknown (probably not very useful)
- String
- Unicode
- Byte
- BigEndianUnicode
- UTF8
- UTF7
- ASCII
Solution
Create Problematic Data
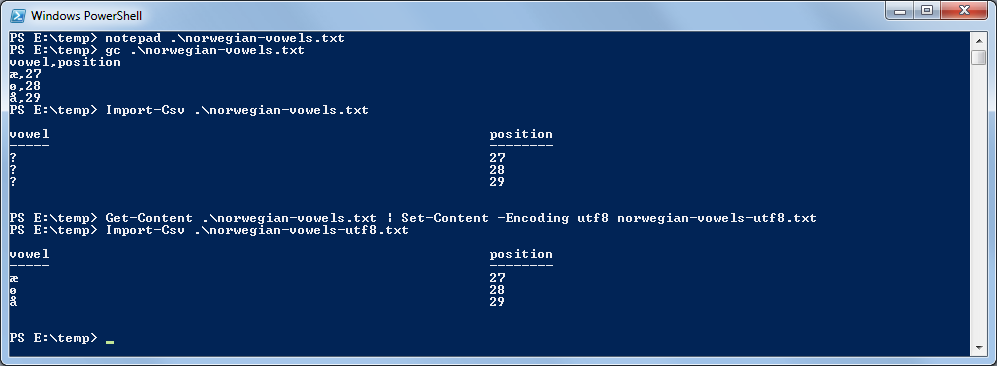
PS C:\> notepad .\norwegian-vowels.txt PS C:\> gc .\norwegian-vowels.txt vowel,position æ,27 ø,28 å,29
Verify It Displays Incorrectly
PS C:\> Import-Csv .\norwegian-vowels.txt vowel position ----- -------- ? 27 ? 28 ? 29
Convert To UTF-8 and Verify It Displays Correctly
Then I just pass it to Import-Csv to verify it's displayed correctly.
PS C:\> Get-Content .\norwegian-vowels.txt |
Set-Content -Encoding utf8 norwegian-vowels-utf8.txt
PS C:\> Import-Csv .\norwegian-vowels-utf8.txt
vowel position
----- --------
æ 27
ø 28
å 29
Additional Information and Avoiding a Temporary File
In looking at why Import-Csv doesn't work as expected found that the missing element is simply the UTF-8 BOM
(see https://en.wikipedia.org/wiki/Byte_order_mark )
The Get-Content cmdlet correctly determines the encoding at UTF-8 if the BOM is present or not, Import-Csv only works if the BOM is present.
I tried specifying the encoding to Import-Csv and that does not work either: PS C:\> Import-Csv -Encoding UTF8 .\norwegian-vowels.txt
You can eliminate the interim file encoding step like this: PS C:\> Get-Content .\norwegian-vowels.txt | ConvertFrom-Csv
I submitted a bug to Microsoft Connect:
https://connect.microsoft.com/PowerShell/feedback/details/1371244/import-csv-does-not-correctly-detect-encoding-for-utf-8-files-without-bomScreenshot Example
keywords: convert from latin1 to utf8 using powershell, convert from latin1 to utf-8, convert from any encoding to utf8, convert from utf7 to utf8, convert from utf16 to utf8, powershell, iconv, linux, converting to utf8, converting file encodings with powershell, converting file encoding with linux, convert file, iso-8859-1-15, iso-8859-1, latin1, incompatible file encoding, characters displayed incorrectly, norwegian vowels incorrectly displayed in powershell, characters incorrectly displayed in powershell, converting files using powershell, excel csv, import-csv, csv latin1, csv iso8859, import-csv utf8, characters display wrong with import-csv in powershell
Powershell Windows Encoding UTF8
Blog articles in alphabetical order
A
- A Look at the KLP AksjeNorden Index Mutual Fund
- A primitive hex version of the seq gnu utility, written in perl
- Accessing the Bing Search API v5 using PowerShell
- Accessing the Google Custom Search API using PowerShell
- Active directory password expiration notification
- Aksje-, fonds- og ETF-utbytterapportgenerator for Nordnet-transaksjonslogg
- Ascii art characters powershell script
- Automatically delete old IIS logs with PowerShell
C
- Calculate and enumerate subnets with PSipcalc
- Calculate the trend for financial products based on close rates
- Check for open TCP ports using PowerShell
- Check if an AD user exists with Get-ADUser
- Check when servers were last patched with Windows Update via COM or WSUS
- Compiling or packaging an executable from perl code on windows
- Convert between Windows and Unix epoch with Python and Perl
- Convert file encoding using linux and iconv
- Convert from most encodings to utf8 with powershell
- ConvertTo-Json for PowerShell version 2
- Create cryptographically secure and pseudorandom data with PowerShell
- Crypto is here - and it is not going away
- Crypto logo analysis ftw
D
G
- Get rid of Psychology in the Stock Markets
- Get Folder Size with PowerShell, Blazingly Fast
- Get Linux disk space report in PowerShell
- Get-Weather cmdlet for PowerShell, using the OpenWeatherMap API
- Get-wmiobject wrapper
- Getting computer information using powershell
- Getting computer models in a domain using Powershell
- Getting computer names from AD using Powershell
- Getting usernames from active directory with powershell
- Gnu seq on steroids with hex support and descending ranges
- Gullpriser hos Gullbanken mot spotprisen til gull
H
- Have PowerShell trigger an action when CPU or memory usage reaches certain values
- Historical view of the SnP 500 Index since 1927, when corona is rampant in mid-March 2020
- How Many Bitcoins (BTC) Are Lost
- How many people own 1 full BTC
- How to check perl module version
- How to list all AD computer object properties
- Hva det innebærer at særkravet for lån til sekundærbolig bortfaller
I
L
M
P
- Parse openssl certificate date output into .NET DateTime objects
- Parse PsLoggedOn.exe Output with PowerShell
- Parse schtasks.exe Output with PowerShell
- Perl on windows
- Port scan subnets with PSnmap for PowerShell
- PowerShell Relative Strength Index (RSI) Calculator
- PowerShell .NET regex to validate IPv6 address (RFC-compliant)
- PowerShell benchmarking module built around Measure-Command
- Powershell change the wmi timeout value
- PowerShell check if file exists
- Powershell check if folder exists
- PowerShell Cmdlet for Splitting an Array
- PowerShell Executables File System Locations
- PowerShell foreach loops and ForEach-Object
- PowerShell Get-MountPointData Cmdlet
- PowerShell Java Auto-Update Script
- Powershell multi-line comments
- Powershell prompt for password convert securestring to plain text
- Powershell psexec wrapper
- PowerShell regex to accurately match IPv4 address (0-255 only)
- Powershell regular expressions
- Powershell split operator
- Powershell vs perl at text processing
- PS2CMD - embed PowerShell code in a batch file
R
- Recursively Remove Empty Folders, using PowerShell
- Remote control mom via PowerShell and TeamViewer
- Remove empty elements from an array in PowerShell
- Remove first or last n characters from a string in PowerShell
- Rename unix utility - windows port
- Renaming files using PowerShell
- Running perl one-liners and scripts from powershell
S
- Sammenlign gullpriser og sølvpriser hos norske forhandlere av edelmetall
- Self-contained batch file with perl code
- Silver - The Underrated Investment
- Simple Morningstar Fund Report Script
- Sølv - den undervurderte investeringen
- Sort a list of computers by domain first and then name, using PowerShell
- Sort strings with numbers more humanely in PowerShell
- Sorting in ascending and descending order simultaneously in PowerShell
- Spar en slant med en optimalisert kredittkortportefølje
- Spre finansiell risiko på en skattesmart måte med flere Aksjesparekontoer
- SSH from PowerShell using the SSH.NET library
- SSH-Sessions Add-on with SCP SFTP Support
- Static Mutual Fund Portfolio the Last 2 Years Up 43 Percent
- STOXR - Currency Conversion Software - Open Exchange Rates API